Forex °ExSan at Work -Current Project°
LINK: About ExSan
Trading of one currency for another with the hopes of taking advantage of small differences in conversion rates among several currencies in order to achieve a profit. For example, if 1.00 in U.S. currency buys 0.7 British pounds currency, 1.00 in British currency buys 9.5 French francs, and 1 French franc buys 0.16 in U.S. dollars, then a forex trader can start with 1.00 USD and earn 1 * 0.7 * 9.5 * 0.16 = 1.064 dollars thus earning a profit of 6.4 percent.
The problem consist to write a program that determines whether a sequence of currency exchanges can yield a profit as described above.
To result in successful trade, a sequence of exchanges must begin and end with the same currency, but any starting currency may be considered.
The input file consists of one or more conversion tables. You must solve the trading problem for each of the tables in the input file. Each table is preceded by an integer $@n@$ on a line by itself giving the dimensions of the table. The maximum dimension is 20. The minimum dimension is 2.
The table then follows in row major order but with the diagonal elements of the table missing (these are assumed to have value 1.0). Thus the first row of the table represents the conversion rates between country 1 and $@n - 1@$ other countries, i.e. the amount of currency of country $@i@$ constrained to $@2 \leq i \leq n@$ that can be purchased with one unit of the currency of country 1.
Thus each table consists of $@n + 1@$ lines in the input file: 1 line containing $@n@$ and $@n@$ lines representing the conversion table.
Output
For each table in the input file, you must determine whether a sequence of exchanges exists that results in a profit of more than 1 percent (0.01). If a sequence exists you must print the sequence of exchanges that results in a profit. If there is more than one sequence that results in a profit of more than 1 percent you must print a sequence of minimal length, i.e. one of the sequences that uses the fewest exchanges of currencies to yield a profit.
Because the IRS (United States Internal Revenue Service) taxes long
transaction sequences with a high rate, all profitable sequences must
consist of $@n@$ or fewer transactions where $@n@$ is the dimension of
the table giving conversion rates. The sequence 1 2 1 represents
two conversions.
If a profitable sequence exists you must print the sequence of exchanges that results in a profit. The sequence is printed as a sequence of integers with the integer $@i@$ representing the $@i@$-th line of the conversion table (country $@i@$). The first integer in the sequence is the country from which the profitable sequence starts. This integer also ends the sequence.
If no profiting sequence of $@n@$ or fewer transactions exists, then the line
no trading sequence existsshould be printed.
Sample Input
3
1.2 .89
.88 5.1
1.1 0.15
4
3.1 0.0023 0.35
0.21 0.00353 8.13
200 180.559 10.339
2.11 0.089 0.06111
2
2.0
0.45Sample Output
1 2 1
1 2 4 1
no trading sequence existsAnalysis
For a given problem, the conversion table corresponds to a graph and the solution corresponds to a shortest profitable cycle in that graph. Consider the following conversion table over USD, MXN, and EUR.
3
1.004987562112089 1.004987562112089
0.99503719020999 1.004987562112089
1.004987562112089 0.99503719020999The table corresponds to the following interpretation.
| USD | MXN | EUR
----------------------------------------------
USD | 0 | 1.01^(1/2) | 1.01^(1/2)
MXN | 1.01^(-1/2) | 0 | 1.01^(1/2)
EUR | 1.01^(1/2) | 1.01^(-1/2) | 0The corresponding graph is the following.
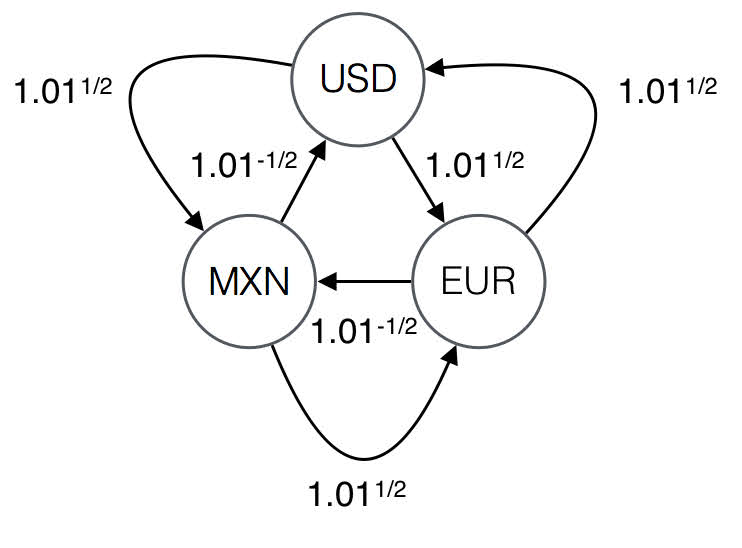
When we interpret the conversion table, we write 0 for the rates in the diagonal to indicate that we do not consider edges that start and end in the same vertex.
The reason is that those edges are redundant.
A lasso is an edge that starts and ends in the same vertex.
Lassos are redundant because from a given sequence that includes a lasso you obtain a shorter sequence with the same rate by removing the lasso.
For example, sequence USD USD EUR USD yields profit 1.01, the same profit that the shorter sequence USD EUR USD yields.
A sequence of exchanges may yield a profit only if the sequence is a cycle.
For example, the cycle USD -> MXN -> EUR -> USD yields profit of $@1.01^{3/2}@$.
Given that the number of vertices in the graph is 3, we do not consider cycles longer than 3.
Consider the cycles of length 3 or less.
CYCLE : RATE
USD -> MXN -> USD : 1
USD -> EUR -> USD : 1.01
EUR -> MXN -> EUR : 1
USD -> MXN -> EUR -> USD : 1.01^(3/2)
USD -> EUR -> MXN -> USD : 1.01^(-1/2)A cycle is profitable when its rate is greater or equal to 1.01. Out of the five cycles, only the following two are profitable.
USD -> EUR -> USD
USD -> MXN -> EUR -> USDOut of the two profitable cycles, USD -> EUR -> USD is the only solution because it is the shortest cycle.
A solution may not be a simple cycle like in the previous example. For example, consider the following conversion table and its corresponding graph.
4
1 0 0
1.005 0 0
0 0 0
0 0 0
For the graph, the cycles of length 4 or less are the following
CYCLE : RATE
1 2 1 : 1.005
1 2 1 2 1 : 1.010025The only profitable cycle is 1 2 1 2 1 and therefore it is the only solution.
The cycle is a solution regardless of the fact that it consists of the repetition of simple cycle 1 2 1.
A solution that is not a simple cycle is not necessarily the repetition of a simple cycle like in the previous example. For example, consider the following conversion table and its corresponding graph.
5
1.001992047666533 0 0 1.001992047666533
1.001992047666533 0 0 0
1.001992047666533 0 0 0
0 0 0 0
0 0 1.001992047666533 0
For the graph, the cycles of length 5 or less are the following.
CYCLE : RATE
1 2 1 : 1.01^(2/5)
1 5 3 1 : 1.01^(3/5)
1 2 1 5 3 1 : 1.01The only profitable cycle is 1 2 1 5 3 1 and therefore it is the only solution.
The cycle consists of simple cycles 1 2 1 and 1 5 3 1.
Searching for a solution is difficult because there may be many cycles for a given problem. The reason is that a conversion table of length $@n@$ corresponds to complete graph $@K_n@$. Even if there are edges with weight 0, we consider them because considering a complete graph makes for a simpler solution. The exception are lassos, which we do not consider because they are redundant. For complete graphs of size $@2 \leq n \leq 20@$, the number of cycles of length $@n@$ or less is the following.
K2: 1
K3: 5
K4: 42
K5: 384
K6: 4,665
K7: 69,537
K8: 1,230,124
K9: 25,140,552
K10: 582,508,305
K11: 15,084,077,381
K12: 431,646,196,806
K13: 13,525,545,361,080
K14: 460,576,563,322,057
K15: 16,935,036,272,292,001
K16: 668,691,718,661,091,000
K17: 28,220,125,532,003,984,176
K18: 1,267,597,789,008,779,578,401
K19: 60,381,304,029,673,985,693,205
K20: 3,040,239,935,992,309,703,757,730Approach
We approach the problem by searching for a shortest profitable cycle amongst a limited number of candidates.
We guarantee that the profitable cycle we find is shortest by considering candidates in order of length.
Consider the following input graph.

The candidates of length 2 are the cycles of length 2. Thus, we consider the cycles of length 2 from each one of the vertices as illustrated in the following diagram. These are all the cycles of length 2 because we consider all paths that start and end in each given vertex.

We search for a profitable candidate of length 2 by considering each root and each corresponding child.
For example, for root 1 and child 2, we consider the following candidate.
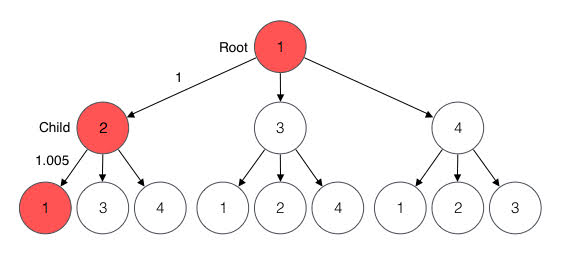
The rate of the candidate is 1.005 which is not profitable and therefore not a solution. We search the rest of the candidates by repeating the process for each root and child. We find no profitable candidate of length 2.
Half of the candidates of length 2 are repeated but we consider them anyway.
For example, candidate for root 2 and child 1 (2 -> 1 -> 2) is the same cycle and candidate for root 1 and child 2 (1 -> 2 -> 1).
The reason we consider repetitions is that when we apply the process to longer candidates, the number of candidates we consider for each length remains 12 while the number of cycles for the length increases.
For example, when we consider candidates of length 4 for the input graph, we consider 12 candidates instead of the 28 cycles of length 4 that exist.
Given that there is no solution of length 2, we search for a profitable candidate of length 3.
The candidates of length 3 are most beneficial cycles of length 3.
The structure of each candidate consists of a prefix edge i -> j and a suffix path j -> k -> i.
For example, the candidate for root 1 and child 2 is the following.

The prefix edge 1 -> 2 is the edge from 1 to 2 given by the input graph.
The suffix path 2 -> 3 -> 1 is a most beneficial path of length 2 from 2 to 1.
In this case the suffix is the most beneficial path of length 2 from 2 to 1.
The rate of the candidate is 1 which is not profitable and therefore not a solution.
Given that there is a candidate for each root and child, we search the rest of the candidates by repeating the process for each root and child.
We find no profitable candidate of length 3.
Candidates are most beneficial paths, for that reason we construct candidates by constructing most beneficial paths.
The construction of most beneficial paths is determined by their structure. Consider the structure a most beneficial path.
p = i -> k -> ... -> j
------------------
|
m edgesThe candidate consists of a prefix edge i -> k and a suffix path k -> ... -> j.
The suffix path is a most beneficial path of length 2 from k to j because p is a most beneficial path.
If the suffix were not most beneficial, p would not be a most beneficial path from i to j because there would be a suffix from k to j with a higher rate.
The rate B'[i,j] of path p is determined by the rate of its edge W[i,k] and the rate of its suffix B[k,j] as follows.
B'[i,j] = W[i,k] * B[k,j]The construction of a most beneficial path corresponds to the calculation of its rate.
For given origin i and destination j vertices, we obtain the rate B[m][i,j] of most beneficial path of length m from the rates of most beneficial paths of length m - 1 as follows.
B[m][i,j] = max { W[i,k] * B[m - 1][k,j] | k in 1 ... n }For the matrix of weights W corresponding to the input graph, the rate of most beneficial paths of length 1 B[1] is W.
It is possible to construct most beneficial paths on demand instead of upfront together with candidates.
We do not explain that approach because the time complexity of the end-to-end algorithm is the same either way.
We do provide an implementation of the approach for reference.
When we construct most beneficial paths, we consider many more paths than the count of candidates. While we consider 12 candidates for each length, we consider 48 paths when we compute most beneficial paths (4 roots times 3 children times 4 destination vertices). We do so because for a given input graph, the number of candidates is constant for each length and thus the total count of paths that we consider is much less than the count of cycles in the graph. Compare the overapproximation $@n^4@$ of count of paths we consider to the number of cycles in the input graph.
NUMBER OF CYCLES NUMBER OF PATHS WE CONSIDER
K2: 1 < 16
K3: 5 < 81
K4: 42 < 256
K5: 384 < 625
K6: 4,665 > 1296
K7: 69,537 > 2401
K8: 1,230,124 > 4096
K9: 25,140,552 > 6561
K10: 582,508,305 > 10000
K11: 15,084,077,381 > 14641
K12: 431,646,196,806 > 20736
K13: 13,525,545,361,080 > 28561
K14: 460,576,563,322,057 > 38416
K15: 16,935,036,272,292,001 > 50625
K16: 668,691,718,661,091,000 > 65536
K17: 28,220,125,532,003,984,176 > 83521
K18: 1,267,597,789,008,779,578,401 > 104976
K19: 60,381,304,029,673,985,693,205 > 130321
K20: 3,040,239,935,992,309,703,757,730 > 160000The overapproximation corresponds to our nested iteration of $@n@$ lengths, $@n@$ roots, $@n@$ children, and $@n@$ destination vertices.
Given that there is no solution of length 3, we search for a profitable candidate of length 4. For root 1 and child 2, the candidate is the following.

The prefix edge 1 -> 2 is given by the input graph.
The suffix path is the most beneficial path of length 3 from 2 to 1.
In this case there is only one most beneficial path, 2 1 2 1.
The rate of the candidate is 1.010025 which is profitable and thus a solution.
We stop and return the solution.
If we repeated the process for the other candidates, we would find no other solution.
Thus, 1 2 1 2 1 is the only solution.
Implementation
The following C program is the ExSan implementation of my own algorithm. For a given weight matrix rate of size n, function S executes algorithm and prints a solution if there is one. If there is no solution, function S prints NO Sequence Exists.